
First I did a simple title search using the tool at ismir.net. This shows that from 2000 - 2009 there were 14 papers with 'playlist' occurring somewhere in the title. Here they are over time:
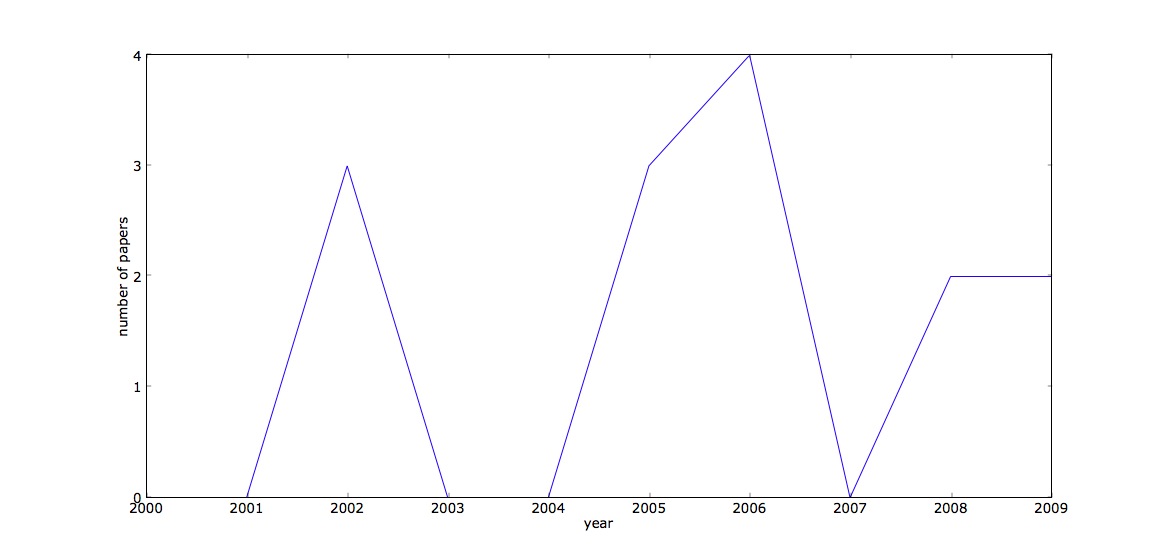
Well, that doesn't show very much, just some interest, no trends or anything. So from there I took a look at the results of at the text search available from Rainer Typke's website. The full text search found some 123 papers mentioning playlist, certainly a few more than the title search. From there I wanted to see what the distribution of these papers was over time (as above), though this took a bit more work, as I couldn't sort out a means to export the search results... Anyway after a bit of counting I got this:
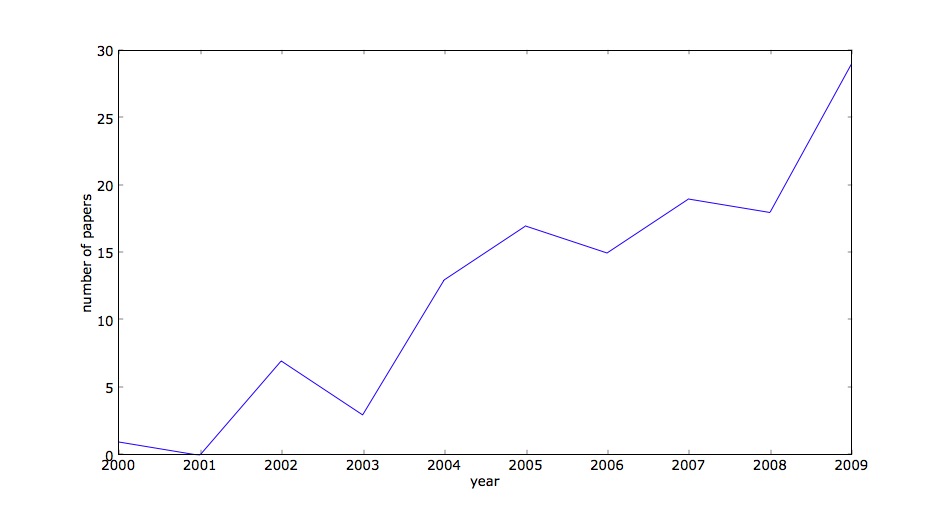
Well, now we're getting somewhere! Clearly there's an increasing number of papers discussing playlists at ISMIR. But wait, you say, this doesn't take into account the considerable expansion of the size of the conference over it's existence. So we can normalize to the number of papers per year that are known the the Cumulative ISMIR proceedings ( [35, 43, 62, 56, 108, 119, 99, 131, 111, 148] from 2000 - 2009 if anyone is interested). Below you can see both the title only and full paper search results normalized to the total number of papers:
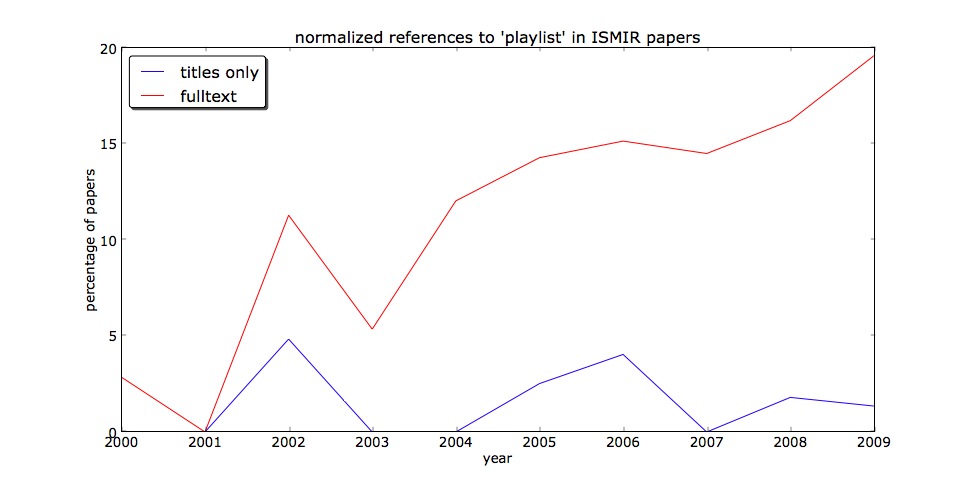
The normalization didn't seem to change the trend much. But this leaves me wondering, what can be drawn from the the massive (and growing) disparity between title mentions and fulltext mentions? Obviously one would expect a higher number of hits, but a tenfold increase, seems very large. My first suspicion is that a great deal of this disparity comes from the fact that many papers at ISMIR that mention playlists are actually about something else (music similarity for instance) and then throw on a playlist as something of an afterthought. Perhaps this is an implicit acknowledgment of the great human-factor power of the playlist (as discussed in for instance this paper) or perhaps it's something else entirely.
Regardless of these finer points, it's clearly fair to say that there is a great deal of interest in playlist generation and analysis. If you're interested in these things, why not sign up for our tutorial?

